
Environmental Incident Reporting: From Blame to Root Cause & System Fixes
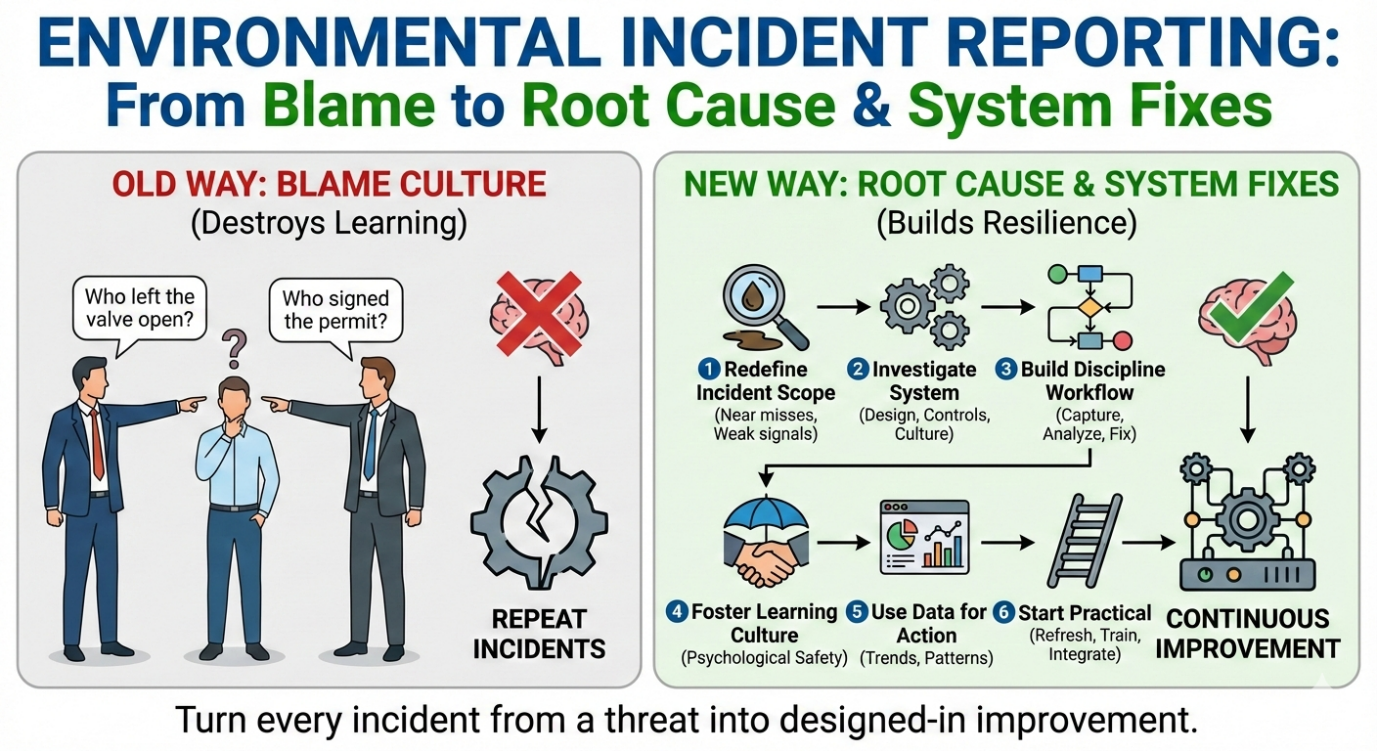
Environmental incidents are still treated in many organisations as “someone messed up, find them and punish them.”
That mindset might feel satisfying in the moment – but it’s terrible risk management.
If you want ESG-credible performance, fewer surprises, and audit-ready evidence, you have to move environmental incident reporting from blame to root cause and system fixes.
This is a shift in operating model, not just a new form template.
1. What we really mean by “environmental incident”
An “environmental incident” isn’t only an oil spill or a regulator at the gate.
A modern incident taxonomy should cover:
- Actual incidents
- Spills, leaks, releases to air, water or soil
- Exceedances of permits or internal limits
- Uncontrolled waste disposal or misclassification
- Serious nuisance (odour, noise, dust) with community impact
- Wildlife/habitat damage on or near your sites
- Near misses
- A valve left open but caught before discharge
- Overfilled bunds that didn’t yet overflow
- Alarms bypassed “just for a while”
- Weak signals
- Repeated small housekeeping issues in chemical stores
- Minor recurring complaints from neighbours
- Frequent small maintenance overrides on pollution control equipment
If you only log “big spills”, you are effectively ignoring your early-warning system.
2. Why blame culture silently kills your incident system
A blame culture looks like this:
- People avoid reporting unless they are forced to.
- Near misses are “handled locally” and never logged.
- Supervisors rewrite the story to protect their own KPIs.
- Root cause analysis is shallow: “operator error” or “did not follow procedure”.
The result?
- You only see the tip of the iceberg – and mostly after damage is done.
- External stakeholders (regulators, investors, communities) don’t trust your narrative.
- The same types of events repeat under slightly different labels.
If your incident dashboard looks clean but your site reality doesn’t, you don’t have strong performance – you have under-reporting.
3. Redesign the intent: from “who’s guilty?” to “what failed in the system?”
The core pivot is simple:
Old question: Who is to blame?
New question: What in our system made this possible or likely?
That means:
- The first objective is to stabilise the situation and protect people and environment.
- The second objective is to understand contributing factors, not just the last person who touched the valve.
- The third objective is to implement and verify system fixes – not just send one more email about “awareness”.
You still keep clear accountability and disciplinary options for wilful violations.
But you treat them as exceptions, not the default explanation.
4. A modern environmental incident workflow
You don’t need something fancy. You need something consistent, auditable, and easy to use.
Step 1 – Capture & classify fast
- Simple digital or paper form that can be completed in minutes.
- Minimum fields:
- What happened (plain language, no storytelling).
- Where and when (location, asset, line, time).
- Type (spill, air emission, noise, waste, etc.).
- Actual impact vs potential impact.
- Was this detected by control system, person, or external party?
- Immediate classification:
- Severity (e.g., S1–S4 based on impact and regulatory exposure).
- Category (air/water/soil/waste/biodiversity/community, etc.).
Near-misses use the same pipeline – just marked as “no actual release” but with high potential.
Step 2 – Contain & document
- Control the source, stop the spread, protect people and environment.
- Record what was done and when: barriers deployed, isolation steps, notifications made.
- Capture photos and key readings (pH, flow rate, dosage, etc.) for evidence trail.
Step 3 – Root cause analysis (for all except trivial issues)
For moderate and high-severity incidents, “operator error” is not acceptable as the final answer.
Use simple but disciplined tools:
- 5 Whys – push at least to the system level, not just behaviour.
- Fishbone / Ishikawa – consider:
- People (competence, fatigue, supervision)
- Methods (procedures, risk assessments, permits)
- Machines (design, maintenance, alarms, safeguards)
- Materials (chemicals, waste streams, compatibility)
- Environment (weather, layout, access, lighting)
- Management (priorities, workload, culture, resources)
Tie every “why” to evidence, not assumptions.
Step 4 – Define corrective & preventive actions (CAPA)
Design actions at system level, not just “retrain operator”:
- Engineering changes (double containment, interlocks, automatic shut-off, level sensors).
- Design changes (simpler pipework, error-proof connections, standardised containers).
- Procedure updates (clear limits, escalation triggers, isolation steps).
- Maintenance upgrades (inspection frequency, critical spares, condition monitoring).
- Controls and monitoring (real-time alarms, trending of critical parameters).
- Governance actions (update risk register, change KPI, adjust roles).
Each action needs:
- Owner
- Due date
- Priority
- Success criteria (how we will know it worked)
Step 5 – Close the loop and verify effectiveness
An incident is not closed when the form is completed.
It is closed when:
- Actions are implemented.
- You verify the change (e.g., mock drills, data trends, audit checks).
- You document the verification outcome.
This is what auditors and regulators look for: “show us what changed”, not just “show us the incident report.”
5. Typical root causes in environmental incidents
If you start doing real root cause work, you’ll see patterns. Common systemic weaknesses include:
- Design gaps
- No proper bunding or bund capacity wrong
- Drains tie process water and stormwater together
- Waste storage lacking clear segregation or impervious flooring
- Control and monitoring gaps
- Alarms poorly set (always in alarm = always ignored)
- Manual sampling only, no trending
- Outdated SOPs that don’t reflect actual process
- Competence and workload issues
- New contractors with no site-specific environmental training
- Over-reliance on one “environmental champion”
- Fatigue and under-staffing on critical shifts
- Supplier and contractor issues
- Waste contractors mixing streams to optimise costs
- Chemical deliveries without consistent labels/MSDS
- Subcontractors bypassing controls to meet schedule
- Governance gaps
- Risk assessments focusing on safety only, not environment
- KPIs that reward production over compliance
- Incidents discussed as “embarrassments” rather than learning opportunities
Design your CAPA system to specifically detect and break these patterns.
6. Building a no-surprises reporting culture
You won’t get better root causes if people are scared to talk.
You need some non-negotiables:
- Clear non-retaliation statement
Reporting an incident or near miss in good faith can never be a reason for punishment. - Leaders go first
Managers openly share incidents, including their own decisions that contributed to risk (“We approved this layout without checking drain mapping…”). - Near misses celebrated, not hidden
Recognise teams that log quality near-miss reports that led to real system fixes. - Separation of process and discipline
- The incident investigation focuses on understanding and system change.
- Disciplinary processes (for deliberate or gross negligence) run in a separate track with higher threshold.
- Feedback loop to the workforce
- “We had X incidents and Y near misses in Q1. These are the top 3 themes, and this is what we’ve changed because you reported them.”
If people see that reporting leads to visible improvements, reporting volume and quality will go up. That’s a sign of a healthier system, not a worse one.
7. Use data to manage risk, not just produce dashboards
A mature organisation treats environmental incident data as a management tool, not just a regulatory chore.
Key analytics that create value:
- Trends by category and severity
Are spills going down but air emission excursions going up? Where and why? - Leading vs lagging indicators
- Lagging: actual incidents, notices of violation, community complaints.
- Leading: near misses, weak signals, overdue actions, bypassed controls.
- Process and asset hot spots
Which lines or activities generate disproportionate incidents? Align with your environmental aspects register. - Recurring root cause themes
If “procedure not followed” keeps coming up, ask: Is the procedure realistic? Is there a design or workload problem? - Action completion vs effectiveness
Many actions closed on time with no impact = cosmetic compliance.
Fewer, well-designed actions that kill whole clusters of incidents = system improvement.
Use this data in management reviews and ESG reports to demonstrate continuous improvement, not just compliance.
8. How to start the shift in your organisation
You don’t have to redesign everything at once. Focus on a small, credible upgrade path:
- Refresh the incident form
- Include near misses and weak signals.
- Remove jargon and make it fast to fill.
- Set a clear incident philosophy
- Short guidance: “We investigate to learn, not to blame. Individual accountability applies only to wilful or reckless behaviour.”
- Train a small cross-functional team in basic root cause tools
- Operations, maintenance, environment, HSE, maybe HR.
- Run real investigations together, not classroom only.
- Select 3–5 recurring incident types
- Apply system-level fixes and measure impact.
- Communicate the before/after story.
- Embed in your management system
- Link incident learning to:
- Environmental aspects & impacts register
- Legal compliance register
- Risk register
- CAPEX planning and design reviews
- Link incident learning to:
This is how you move from a reactive “clean up and move on” culture to a deliberate, learning-driven environmental management system.
9. The bottom line
If your incident reporting process ends with “who did it?” you will keep paying for the same mistakes.
If it ends with “what in our system allowed this, and how do we fix that permanently?”, you will:
- Protect the environment more effectively
- Build trust with regulators, communities, and auditors
- Strengthen your ESG story with evidence, not narratives
- Reduce long-term cost and disruption from repeat events
Environmental incident reporting is not about filling forms.
It’s about turning every deviation – big or small – into structured intelligence for better design, better control, and better decisions.
That’s the pivot: from blame to root cause, to system fixes.Environmental incidents are still treated in many organisations as “someone messed up, find them and punish them.”
That mindset might feel satisfying in the moment – but it’s terrible risk management.
If you want ESG-credible performance, fewer surprises, and audit-ready evidence, you have to move environmental incident reporting from blame to root cause and system fixes.
This is a shift in operating model, not just a new form template.
1. What we really mean by “environmental incident”
An “environmental incident” isn’t only an oil spill or a regulator at the gate.
A modern incident taxonomy should cover:
- Actual incidents
- Spills, leaks, releases to air, water or soil
- Exceedances of permits or internal limits
- Uncontrolled waste disposal or misclassification
- Serious nuisance (odour, noise, dust) with community impact
- Wildlife/habitat damage on or near your sites
- Near misses
- A valve left open but caught before discharge
- Overfilled bunds that didn’t yet overflow
- Alarms bypassed “just for a while”
- Weak signals
- Repeated small housekeeping issues in chemical stores
- Minor recurring complaints from neighbours
- Frequent small maintenance overrides on pollution control equipment
If you only log “big spills”, you are effectively ignoring your early-warning system.
2. Why blame culture silently kills your incident system
A blame culture looks like this:
- People avoid reporting unless they are forced to.
- Near misses are “handled locally” and never logged.
- Supervisors rewrite the story to protect their own KPIs.
- Root cause analysis is shallow: “operator error” or “did not follow procedure”.
The result?
- You only see the tip of the iceberg – and mostly after damage is done.
- External stakeholders (regulators, investors, communities) don’t trust your narrative.
- The same types of events repeat under slightly different labels.
If your incident dashboard looks clean but your site reality doesn’t, you don’t have strong performance – you have under-reporting.
3. Redesign the intent: from “who’s guilty?” to “what failed in the system?”
The core pivot is simple:
Old question: Who is to blame?
New question: What in our system made this possible or likely?
That means:
- The first objective is to stabilise the situation and protect people and environment.
- The second objective is to understand contributing factors, not just the last person who touched the valve.
- The third objective is to implement and verify system fixes – not just send one more email about “awareness”.
You still keep clear accountability and disciplinary options for wilful violations.
But you treat them as exceptions, not the default explanation.
4. A modern environmental incident workflow
You don’t need something fancy. You need something consistent, auditable, and easy to use.
Step 1 – Capture & classify fast
- Simple digital or paper form that can be completed in minutes.
- Minimum fields:
- What happened (plain language, no storytelling).
- Where and when (location, asset, line, time).
- Type (spill, air emission, noise, waste, etc.).
- Actual impact vs potential impact.
- Was this detected by control system, person, or external party?
- Immediate classification:
- Severity (e.g., S1–S4 based on impact and regulatory exposure).
- Category (air/water/soil/waste/biodiversity/community, etc.).
Near-misses use the same pipeline – just marked as “no actual release” but with high potential.
Step 2 – Contain & document
- Control the source, stop the spread, protect people and environment.
- Record what was done and when: barriers deployed, isolation steps, notifications made.
- Capture photos and key readings (pH, flow rate, dosage, etc.) for evidence trail.
Step 3 – Root cause analysis (for all except trivial issues)
For moderate and high-severity incidents, “operator error” is not acceptable as the final answer.
Use simple but disciplined tools:
- 5 Whys – push at least to the system level, not just behaviour.
- Fishbone / Ishikawa – consider:
- People (competence, fatigue, supervision)
- Methods (procedures, risk assessments, permits)
- Machines (design, maintenance, alarms, safeguards)
- Materials (chemicals, waste streams, compatibility)
- Environment (weather, layout, access, lighting)
- Management (priorities, workload, culture, resources)
Tie every “why” to evidence, not assumptions.
Step 4 – Define corrective & preventive actions (CAPA)
Design actions at system level, not just “retrain operator”:
- Engineering changes (double containment, interlocks, automatic shut-off, level sensors).
- Design changes (simpler pipework, error-proof connections, standardised containers).
- Procedure updates (clear limits, escalation triggers, isolation steps).
- Maintenance upgrades (inspection frequency, critical spares, condition monitoring).
- Controls and monitoring (real-time alarms, trending of critical parameters).
- Governance actions (update risk register, change KPI, adjust roles).
Each action needs:
- Owner
- Due date
- Priority
- Success criteria (how we will know it worked)
Step 5 – Close the loop and verify effectiveness
An incident is not closed when the form is completed.
It is closed when:
- Actions are implemented.
- You verify the change (e.g., mock drills, data trends, audit checks).
- You document the verification outcome.
This is what auditors and regulators look for: “show us what changed”, not just “show us the incident report.”
5. Typical root causes in environmental incidents
If you start doing real root cause work, you’ll see patterns. Common systemic weaknesses include:
- Design gaps
- No proper bunding or bund capacity wrong
- Drains tie process water and stormwater together
- Waste storage lacking clear segregation or impervious flooring
- Control and monitoring gaps
- Alarms poorly set (always in alarm = always ignored)
- Manual sampling only, no trending
- Outdated SOPs that don’t reflect actual process
- Competence and workload issues
- New contractors with no site-specific environmental training
- Over-reliance on one “environmental champion”
- Fatigue and under-staffing on critical shifts
- Supplier and contractor issues
- Waste contractors mixing streams to optimise costs
- Chemical deliveries without consistent labels/MSDS
- Subcontractors bypassing controls to meet schedule
- Governance gaps
- Risk assessments focusing on safety only, not environment
- KPIs that reward production over compliance
- Incidents discussed as “embarrassments” rather than learning opportunities
Design your CAPA system to specifically detect and break these patterns.
6. Building a no-surprises reporting culture
You won’t get better root causes if people are scared to talk.
You need some non-negotiables:
- Clear non-retaliation statement
Reporting an incident or near miss in good faith can never be a reason for punishment. - Leaders go first
Managers openly share incidents, including their own decisions that contributed to risk (“We approved this layout without checking drain mapping…”). - Near misses celebrated, not hidden
Recognise teams that log quality near-miss reports that led to real system fixes. - Separation of process and discipline
- The incident investigation focuses on understanding and system change.
- Disciplinary processes (for deliberate or gross negligence) run in a separate track with higher threshold.
- Feedback loop to the workforce
- “We had X incidents and Y near misses in Q1. These are the top 3 themes, and this is what we’ve changed because you reported them.”
If people see that reporting leads to visible improvements, reporting volume and quality will go up. That’s a sign of a healthier system, not a worse one.
7. Use data to manage risk, not just produce dashboards
A mature organisation treats environmental incident data as a management tool, not just a regulatory chore.
Key analytics that create value:
- Trends by category and severity
Are spills going down but air emission excursions going up? Where and why? - Leading vs lagging indicators
- Lagging: actual incidents, notices of violation, community complaints.
- Leading: near misses, weak signals, overdue actions, bypassed controls.
- Process and asset hot spots
Which lines or activities generate disproportionate incidents? Align with your environmental aspects register. - Recurring root cause themes
If “procedure not followed” keeps coming up, ask: Is the procedure realistic? Is there a design or workload problem? - Action completion vs effectiveness
Many actions closed on time with no impact = cosmetic compliance.
Fewer, well-designed actions that kill whole clusters of incidents = system improvement.
Use this data in management reviews and ESG reports to demonstrate continuous improvement, not just compliance.
8. How to start the shift in your organisation
You don’t have to redesign everything at once. Focus on a small, credible upgrade path:
- Refresh the incident form
- Include near misses and weak signals.
- Remove jargon and make it fast to fill.
- Set a clear incident philosophy
- Short guidance: “We investigate to learn, not to blame. Individual accountability applies only to wilful or reckless behaviour.”
- Train a small cross-functional team in basic root cause tools
- Operations, maintenance, environment, HSE, maybe HR.
- Run real investigations together, not classroom only.
- Select 3–5 recurring incident types
- Apply system-level fixes and measure impact.
- Communicate the before/after story.
- Embed in your management system
- Link incident learning to:
- Environmental aspects & impacts register
- Legal compliance register
- Risk register
- CAPEX planning and design reviews
- Link incident learning to:
This is how you move from a reactive “clean up and move on” culture to a deliberate, learning-driven environmental management system.
9. The bottom line
If your incident reporting process ends with “who did it?” you will keep paying for the same mistakes.
If it ends with “what in our system allowed this, and how do we fix that permanently?”, you will:
- Protect the environment more effectively
- Build trust with regulators, communities, and auditors
- Strengthen your ESG story with evidence, not narratives
- Reduce long-term cost and disruption from repeat events
Environmental incident reporting is not about filling forms.
It’s about turning every deviation – big or small – into structured intelligence for better design, better control, and better decisions.
That’s the pivot: from blame to root cause, to system fixes.